自定义AI声音翻唱:分步指南
本教程将解释如何创建您自己的AI歌声,并使用MusicArt将其应用于歌曲翻唱。
简介
MusicArt允许您从自己的录音中训练出独特的AI声音模型,并将该声音应用于现有歌曲。 此工作流程专为希望实现人声个性化,而无需麦克风、录音棚或高级制作技能的创作者设计。
开始使用
训练您的声音模型 打开AI歌声生成器。 为您的声音模型输入一个名称,然后上传您的人声录音以开始训练。
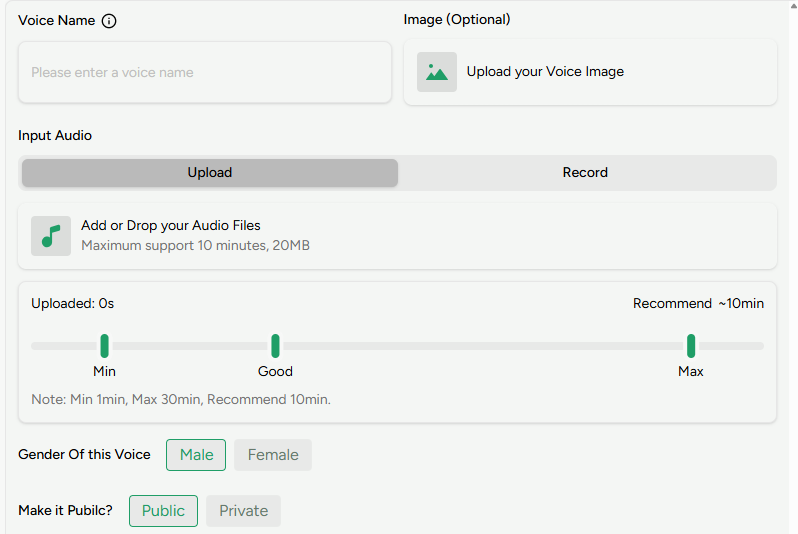
训练您的声音模型
您可以上传音频文件,或直接在浏览器中录制。支持的总时长范围为1到30分钟。 为获得最准确的结果,请提供至少10分钟的纯净人声音频,不含背景噪音、混响、回声或音乐。 上传后,选择人声性别,并选择模型是公开还是私有。公开模型可能会出现在共享声音库中,供其他用户探索。
生成您的AI歌曲翻唱
打开AI歌曲翻唱生成器。 您将看到两个选项:“我的声音模型”和“库”。
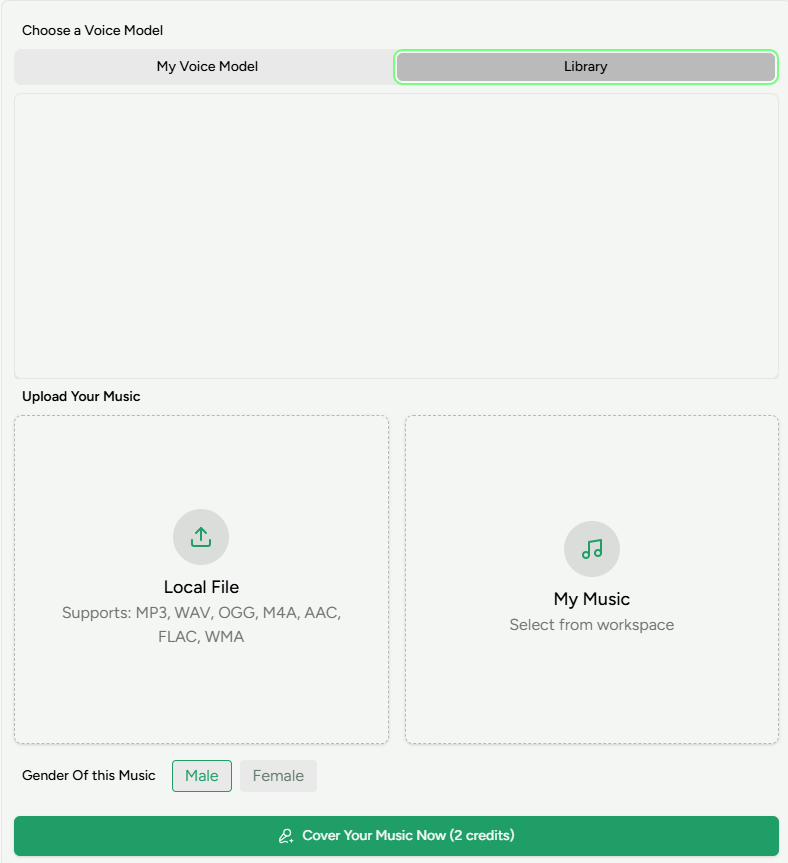
- 在“我的声音模型”下选择您已训练的声音模型之一,或从“库”中选择一个预设声音。
- 上传您想要翻唱的歌曲,或从“我的音乐”中选择您之前在MusicArt上创建的曲目。
- 为翻唱设置人声性别,因为这会直接影响生成的歌声。
- 点击“翻唱”按钮,等待约1-2分钟进行处理。
处理完成后,预览翻唱并下载最终音频。